")
In the last years, we have all witnessed the surge in AI Agents and Low-Code automations built around Generative AI. Several organizations have even started adopting AI-Chatbots built on specialized knowledge systems. However, the Return on Investment (ROI) was often stifled by the high cost of infrastructure and the niche IT expertise required.
That picture is about to change dramatically in 2026! Enterprises are expected to breakthrough into hyper-specialized agents, without breaking through the six-figure costs of setting up the Retrieval Augmented Generation (RAG data base) and complex Data Pipelines.
Why?
The “Big Three” AI-Hyperscalers have been steadily building “Managed RAG” cloud-solutions. These managed infrastructures are not General Intelligence; they enable highly specialized, narrow knowledge systems and AI Agents that can operate with high accuracy (and no hallucinations). Hence, they prove to be a credible alternative to cumbersome DIY builds, and costly on-premise options.

So, what exactly has changed?
Why is it significant?
And what pitfalls to avoid while implementing?
Before we dive deeper, let’s quickly clarify the key concepts at the heart of this trend:
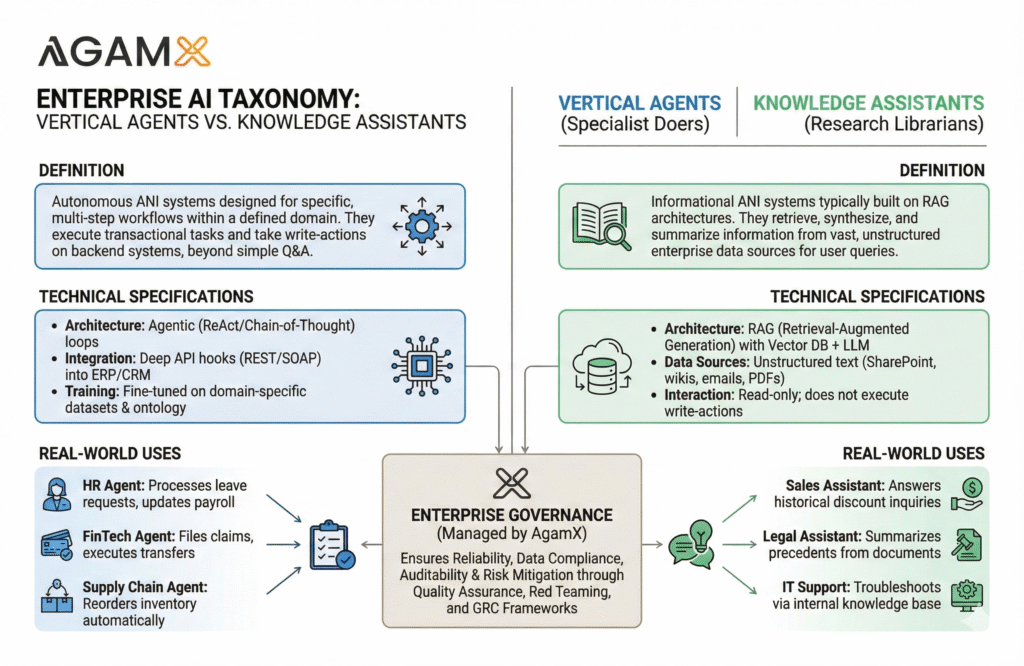
Vertical Agents are highly specialized ANI (Artificial Narrow Intelligence) systems designed to execute specific workflows within a defined vertical or domain (e.g., Supply Chain, HR, FinTech). Unlike a general-purpose LLM (Large Language Model) that knows a little about everything, a vertical agent is fine-tuned on company-specific ontology and is integrated with backend systems (APIs) to perform transactions. They don’t just answer questions; they file claims, perform fraud-analysis, or reorder inventory.
Knowledge Assistants are the knowledge back-bones behind the vertical agents. Built typically on RAG (Retrieval-Augmented Generation) architectures, they ingest vast amounts of unstructured enterprise data (PDFs, wikis, emails) as well as structured data (databases, excels) and allow users to query it in natural language. They do not typically execute write-actions to databases; instead, they focus on surfacing the “right” answer from a sea of internal documentation, based on the context of the user.
So what is new with enterprise knowledge assistants?
The promise of generative AI in the enterprise has shifted from novel content creation to practical knowledge retrieval. Businesses are less interested in asking an AI to write a customer email, but more focused on asking it: “What is the liability limitation for Client X vs Y, in the past 10 years?”
This capability requires Retrieval-Augmented Generation (RAG)—grounding an AI model with company-specific, private data. Traditionally, to build an AI Chatbot, you had to build the “filing system” yourself—chopping documents into segments, converting them into mathematical vectors, storing them in a specialized database, and writing complex code to retrieve the right chunks. Furthermore, the data security and privacy concerns on such a “DIY” RAG have rendered it practically unthinkable for most organizations in regulated industries, and for the right reasons!
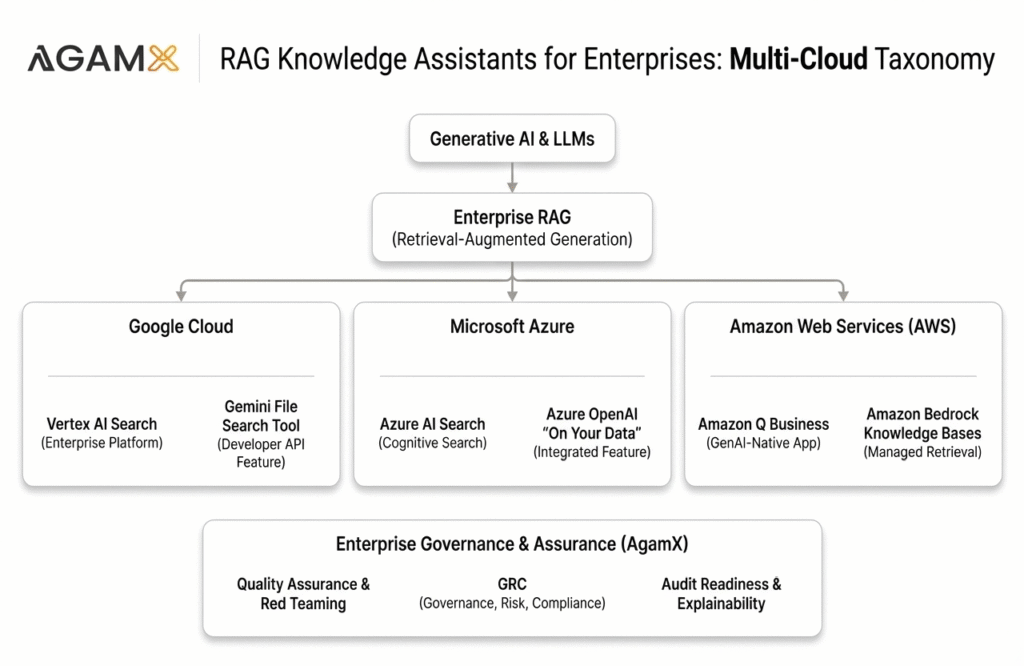
Recently, the major cloud providers have responded to this by launching Managed RAG; Infrastructure as a Service. These tools provide a “RAG-in-a-box” approach, abstracting the complex backend into simple API calls. Whether it is Google’s Vertex AI Search, AWS’s Knowledge Bases for Bedrock, or Azure’s OpenAI “On Your Data,” the goal is the same: democratize access to narrow intelligence.
“While the technology got simplified, the reliability, governance and data compliance is not guaranteed”
Managed RAG services abstract this entire process. You point the service to your data (in S3, Blob Storage, or Google Cloud Storage), and the cloud provider handles the ingestion, chunking, embedding, and retrieval ranking automatically.
For enterprise CTOs and architects, the choice often depends on the existing cloud footprint. However, each provider has distinct strengths and architectural philosophies.
Ensuring EU Data Sovereignty
All three providers offer “easy” developer tools that look identical to their enterprise counterparts, but require expertise to implement with necessary legal protections and compliance. To be compliant with GDPR and the EU AI Act, you must carefully configure these services for enterprise-tier data security and EU data residency.
Here are the common issues to avoid while setting up in Managed RAG:
- Silent Regional Failover: To ensure uptime, cloud services often replicate data across regions. Without specific “Data Residency” policies enforced at the organization level, a temporary outage in Frankfurt could cause your sensitive data to silently failover to a server in Virginia, immediately violating GDPR transfer restrictions.
- The Training Loophole: Many managed AI services have a default setting that allows the provider to use your interaction data to “improve their models.” For a regulated entity, this is catastrophic. It effectively leaks proprietary knowledge into a public model ecosystem.
- Metadata Leakage: Even if your storage bucket is in the EU, the inference engine (the GPU cluster processing the query) might be located elsewhere to optimize costs. While the file stays in Europe, the data packet traveling to the model does not.
Focus on Quality Assurance and GRC
Deploying specialized Knowledge Assistants is 20% technology and 80% governance. Organizations eager to ship products, must also ensure the internal expertise or external know-how required for rigorous Quality Assurance (QA) or the specialized knowledge for Governance, Risk, and Compliance (GRC).
This is where a specialist partner and internal expertise can become relevant:
- Vendor-Neutral Red-Teaming: Whether you build on AWS, Azure, or Google, the risk of hallucination exists. Adversarial testing to find ways to break the system and ensure it answers “I don’t know” when data is missing. Adopting the OWASP AI Testing framework is highly recommended.
- GRC and EU AI Act Readiness: AI Agents are often manipulated into adopting a hostile tone, outputting biased advice, or agreeing to unethical user requests. Ensuring a robust Agent design, the safety protocols, and EU AI Act Guardrails a MUST—regardless of the underlying cloud.
- Audit Readiness: When regulators ask, “How do you know this bot isn’t giving biased advice?”, the organization need to be fully prepared to provide the validation frameworks, test evidences and audit trails to answer confidently.
Ready to deploy Knowledge Assistants responsibly?
The “Managed RAG” tools from Google, AWS, and Azure represent a massive leap forward in making enterprise data conversational, cost effective and with each having their own legacy of strengths and limitations.
However, ease of use is not a substitute for due diligence. For enterprises, the path to success lies in choosing the right enterprise environment, security concepts and engaging independent specialists to ensure that your narrow intelligence application remains compliant, reliable, and trustworthy.
Explore how Project Support Agents can empower your management layer..
- Click Here to Take Our “AI Readiness Self-Assessment“ – Find out if your organisation is ready for Agentic AI.
- Prefer to see the DEMO and talk to us? Contact Us Directly to book a consultation on deploying your first Project Support AI Agent.
Looking forward to hearing from you!